
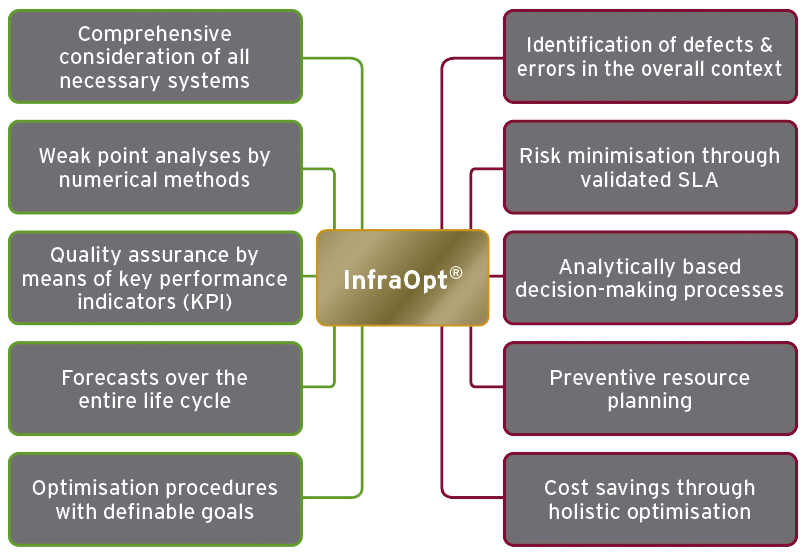
Resilience as a management foundation
... in design
... in planning
... in operation
Data centres that are subjected to resilience analysis during the design phase promise the best results.
Optimisation steps can thus be incorporated into the planning.
Continuous monitoring ensures uninterrupted operation over the entire life cycle.
Our proven process:
Does the "optimal data centre" exist?
InfraOpt® answers this question with yes!
However, the optimal data centre is always dependent on the specific requirements, taking into account the given possibilities.
The European EN 50600 series of standards and their international counterparts ISO/IEC 22237 and ISO/IEC 30134 play a central role here.

Our contribution to standardisation
In data centre practice, it is helpful to have standardised definitions of SLAs. Compliance can be measured using meaningful key performance indicators (KPIs) that quantify the different aspects of resilience.
KPI for data centre resilience
Through the German Commission for Electrical Engineering („Deutsche Kommission für Elektrotechnik“ (DKE)), a working group has been set up, dedicated to the KPI for resilience. The following topics are introduced as an international standardisation proposal ISO/IEC TS 22237-31:

Resilience as the basis of service level agreements
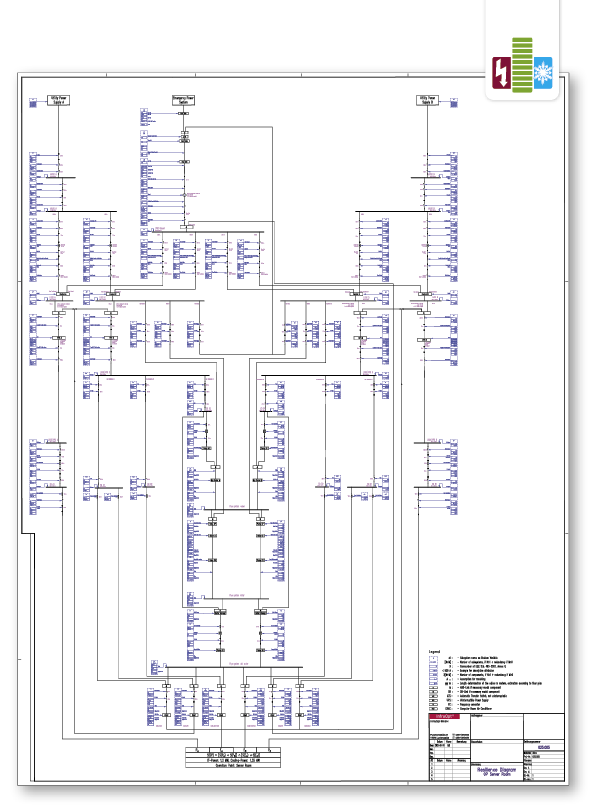
The resilience diagram
The first step in the resilience analysis is the creation of the resilience diagram. Developed by subject matter experts, it includes the following details:
All relevant subsystems of the infrastructure
All functional links between the subsystems
References to the components that make up the subsystems
Definition of the operation point (OP)
What aspects should an SLA cover?
Availability class according to EN 50600-1 or ISO/IEC 22237-1
Reporting period in years
Maximum number of service violations allowed
in the reporting period
Maximum permissible period of unavailability
in the reporting period
Maximum number of 1-point faults (SPoF)
of the infrastructure
Availability calculated on the infrastructure model
Holistic planning with the help of resilience optimisation
Analysts transform the resilience diagram into the simulation software InfraOpt64. The subsystems receive data and properties so that a model of the infrastructure under investigation is created.
On this infrastructure model, SLAs can be validated as well as targeted optimisations of resilience aspects can be carried out by:
Calculating reliability
Calculation of inherent and operational availability
Calculation of 1- and 2-fault tolerance
Calculation of the reduced availability in the 1- and 2-fault case
Blackout simulation
Design variations with different redundancies
Analyses with reduced load
Comparison of different subsystems
Importance analyses
... and much more
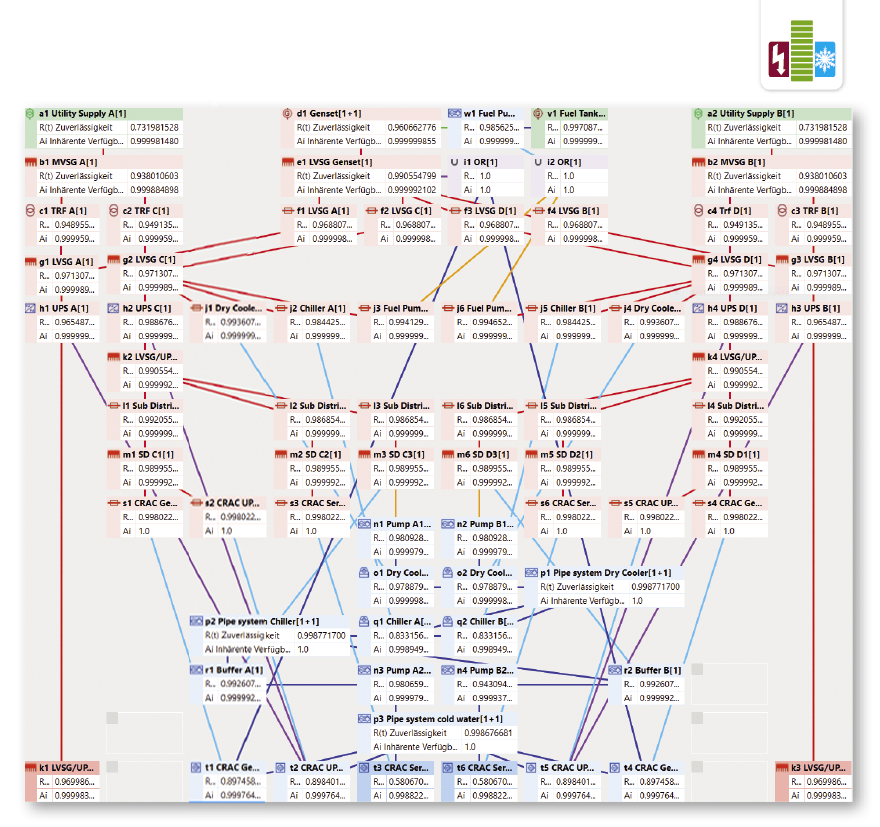
1 Comparative resilience analysis of data centre infrastructures.
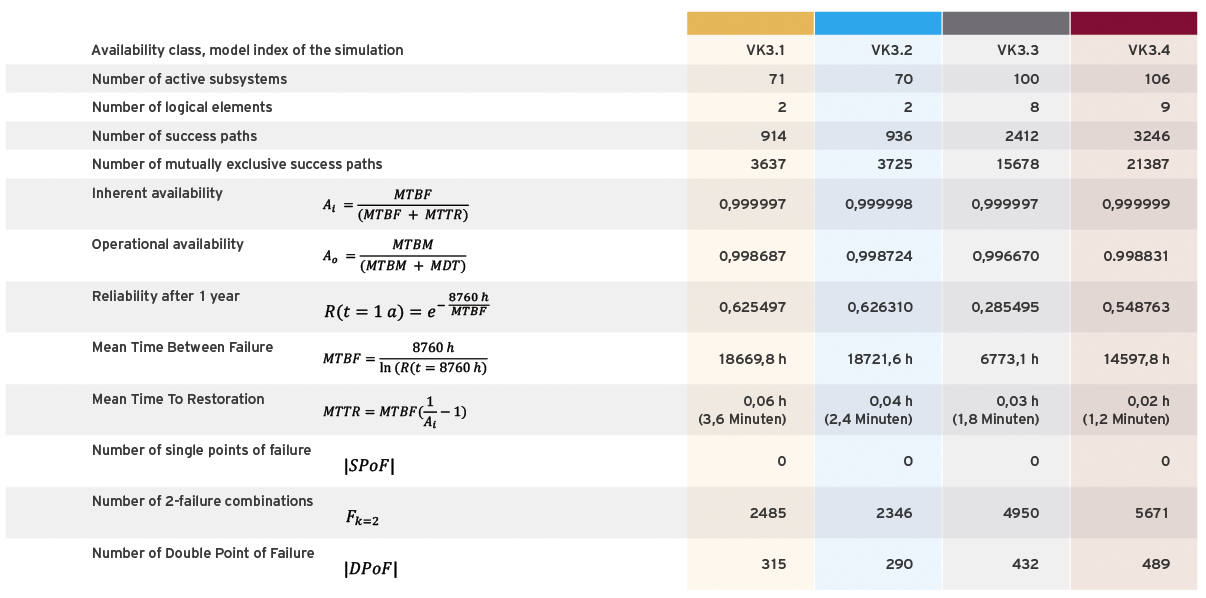
2 Graphical comparison of the analysis results
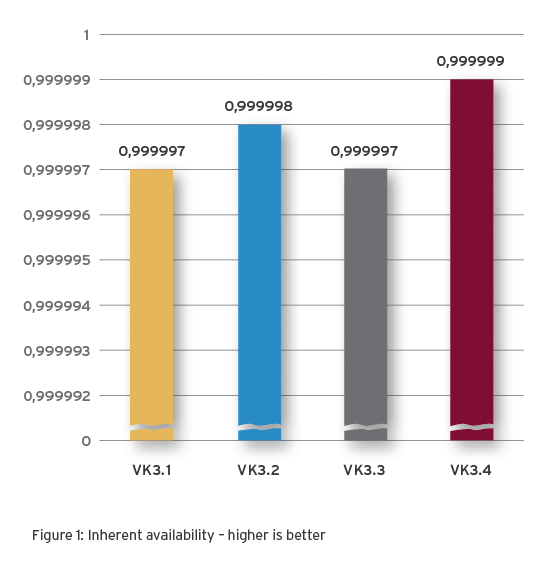
What does Inherent Availability mean?
Inherent availability is a KPI for the probability that the infrastructure will function as expected under ideal operating and maintenance conditions.
It does not take into account times for repair initiation, spare parts procurement or logistics.
As an aspect of resilience, Inherent Availability has the following practical significance:
Application in the design or planning phases
Comparison of variants
Determination of redundancies
Dependent on the metrics MTBF and MTTR
What does Mean Time Between Failure (MTBF) mean?
MTBF quantifies the average time between successive failures.
successive failures.
What does Mean Time To Restoration (MTTR) mean?
MTTR quantifies the average time to repair or replace, excluding delays due to logistics, such as mobilisation, procurement, etc.
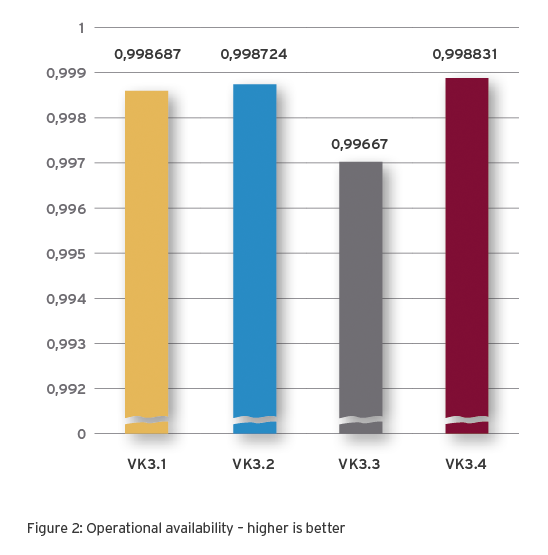
What does Operational Availability mean?
Operational availability is a KPI for the probability that the infrastructure will function as expected under the given operating and maintenance conditions.
Planned and unplanned events as well as required times for logistics are taken into account.
As an aspect of resilience, Operational Availability has the following practical significance:
Sensitive to infrastructure optimisation
Basis for maintenance and repair plans
Usable for logistics planning and material stockpiling
Dependent on the metrics MTBM and MDT
What does Mean Time Between Maintenance (MTBM) mean?
MTBM quantifies the average time between all maintenance events, whether planned or unplanned, including the time for required logistics.
What does Mean Down Time (MDT) mean?
MDT quantifies the average downtime period, including time for required logistics.
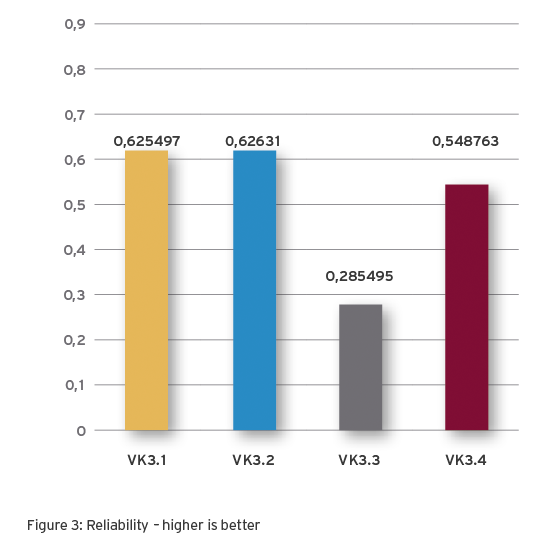
What does reliability mean?
Reliability is KPI for the probability that the infrastructure will function without error, within a given period of time, under acceptable operating conditions.
As an aspect of resilience, reliability has the following practical significance:
Sensitivity to infrastructure optimisation
Determination of redundancies
Predictive repair or replacement
Dependent on MTBF and operating time
What is a repairable system?
Depending on inherent redundancies, the failure of a subsystem does not necessarily lead to the total failure of the system.
of the system. In a repairable system, such as the data centre infrastructure, the faulty subsystem can be restored to its nominal state through
the faulty subsystem can be restored to its nominal state by repair or replacement

What does fault tolerance mean?
Fault tolerance of an infrastructure refers to the ability of one or more subsystems to continue to function as intended in the event of a failure.
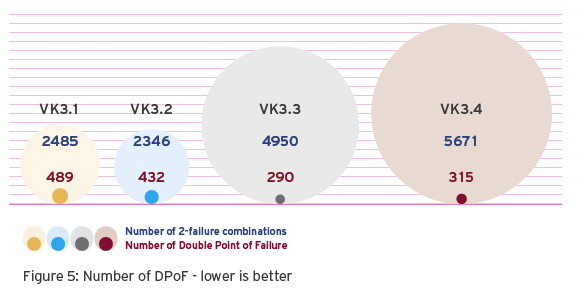
Single Point of Failure (SPoF) refers to a subsystem whose failure results in the infrastructure no longer functioning as intended.
Double Point of Failure (DPoF) refers to two subsystems whose simultaneous failure means that the function of the infrastructure is no longer given.
It is initially irrelevant whether the cause of failures are failures or maintenance measures.
The ability to absorb errors or to quickly return to the nominal state after errors are aspects of resilience.
The KPI of fault tolerance, measured as the number of SPoF and DPoF, are subject to optimisation.